I trained a Neural Network to predict final exam scores of my classmates
TLDR;
In this blog, I share my experience of training a neural network to predict the final exam scores of my classmates. I used Python to build a Multilayer Perceptron (MLP), a type of Artificial Neural Network (ANN), to create a model having input layer with 4 nodes, two hidden layers with 5 and 4 nodes, and an output layer with 1 node. I used Rectified Linear Unit (ReLU) (top right in image) activation function and Stochastic Gradient Descent (SGD) optimizer for training. The model’s objective was to estimate the final exam marks based on previous semester internal exam scores, subject difficulty, and student ratings. I devised a method to estimate the final exam marks from available grade information. Data preparation was frustrating, but after training the model, it made predictions that seemed promising. I also explored alternative approaches like Multiple Regression and Automatic Relevance Determination Regression (ARD), but chose Neural Network for its ability to understand non-linear relationships. I plan to evaluate the model’s accuracy once the final exam results are declared.

The list of libraries I used includes numpy, pandas and scikit-learn.
Understanding the evaluation system
Before we get into the main part, I would like to discuss the evaluation system. My college has two internal exams of 60 marks each and a final exam of 70 marks. The first internal exam covers almost 45% syllabus and the second covers ~80%. Both internal marks are summed and converted into a range of 30 (divided by 4), this are the final internal marks. If the sum is greater than or equal to 48, then four marks are added to that converted score. Other than this, there are bonus marks (out of 16 if present in first four days else 12) based on your attendance which are added to your internals of that subject as per need. These internals (out of 30) and final exam scores (out of 70) are summed up to get the final grade.
The final grade is calculated as follows:
85–100: AA (10 points), 75–84: AB (9 points)
65–74: BB (8 points), 55–64: BC (7 points)
45–54: CC (6 points), 40–44: CD (5 points)
35–39: DD (4 points), 0–34: FF (0 points)
The grade point of each subject is multiplied to its credit. These products are summed up and divided by the sum of all the credit points which will give you the SPI or GPA.
Data preparation
The thing I found the most frustrating was data preparation. I had to gather the previous semester’s data as well as the current semester data in proper format. I got students’ roll numbers, both internal exam marks of each subject of both semesters, attendance and a column named full which will have either 0 if they were absent in any lecture in the first four days else 1 of this semester. I also had to gather previous semester final grades and the internals.
I had decided to train the neural network on four variables:
- Previous Semester internal exam 1 marks
I multiplied the marks by0.45as they have less syllabus covered and doesn’t truly indicate a student’s performance in the final exam. - Previous Semester internal exam 1 marks
I multiplied the marks by0.8as they cover almost whole syllabus so I thought they matter more. - Subject difficulty on a scale of 1–5
All subjects have their own difficulty so it also plays a role. - Student rating of previous semester
Our college ranks gives students roll numbers based on the total of their internal exam marks of the previous semester. I thought of giving a rating to each student so as to get an idea about how well they can perform in exams. Roll number 1 gets a 1000 rating and with each roll number, it decreases by 5. If a student having good roll number gets a very low roll number in next semester, it implies a drop in potential and vice versa.1000 - (roll no - 1) * 5
The known output for the input data was the final exam marks. I had encountered a problem for this. In reality, we only get to know our internal marks out of 30 and for the final exam, we only get grades. I came up with a way to estimate the final exam marks of a student. As I had mentioned previously, having grade and internal marks can get you the range in which your final exam marks lie. I assumed ceil of the midpoint of the range to be their final exam marks.
For example, if a student has 26 in internals and their grade is AB then:
- 85–26 =
59 - AB imples that their marks lie in the range (59–10 =
49) to58 - Mid point of the range 49–58 is
53.5and ceil(53.5) =54 - The student’s final marks are estimated to be 54.
Below is the python script that does exactly the same thing.
grade_mapping = {
'AA': 0,
'AB': 10,
'BB': 20,
'BC': 30,
'CC': 40,
'CD': 45,
'DD': 50
}
def score(grade, internal):
r = grade_mapping[grade]
mark = 85 - r - internal
if r == 0:
mark = (mark + 70) / 2
elif r <= 40 and r >= 10:
mark = (mark * 2 + 9) / 2
elif r > 40 and r <= 50:
mark = (mark * 2 + 4) / 2
return ceil(mark)Training the Neural Network (MLPRegressor) and making predictions
Now its time to train the model as the data is prepared. The first step is to decide how many hidden layers will your neural network have, number of nodes in each layer, the activation function to use and optimizer. This part is the most important. I told this in the beginning. I experimented with different architectures and selected the one (two hidden layers with 5 and 4 nodes) that seemed to give better results. I used ReLU as it was the most popular, proved to be better and better overcomes the vanishing gradient problem (it also sounds cool). The neural network was fed in those four variables and the final exam score as known output. With each iteration, the neural network adjusts its weights and bias and it gets better at prediction. Neural network sees the input data and the output it resulted in and learns the relationship between them. The more data you have and the more iterations it goes through, the better the model gets. All the values of the variables were scaled using StandardScaler before training as they all are in different ranges.
After I trained the model, I passed the current semester data as inputs to the model and it outputted the final exam grade for each subject. I ceiled the predicted scores.
# Pseudocode for Training the Neural Network
# Step 1: Prepare the data
Create empty lists X and y to store input features and corresponding output labels
for each student in the dataset:
Calculate weighted semester 1 internal exam 1 (s1m1) and internal exam 2 (s1m2) scores
Get the student rating (rating1)
for each subject:
Add the input features [s1m1, s1m2, subject_difficulty_sem1, rating1] to X
Add the corresponding final exam score to y
Convert X and y to numpy arrays
# Step 2: Train the neural network
Initialize the MLPRegressor model with chosen parameters:
- Hidden layer sizes: (5, 4) (two hidden layers with 5 and 4 nodes)
- Activation function: ReLU (Rectified Linear Unit)
- Optimizer: Stochastic Gradient Descent (SGD)
- Random state: 43 (for reproducibility)
- Max iterations: 500
Initialize the StandardScaler to scale the input features
Scale the input features using the StandardScaler
Train the model using the scaled input features (X_scaled) and the output labels (y)
# Pseudocode for Preparing Unseen Data and Predicting Semester 2 Final Scores
# Step 1: Prepare unseen data for prediction
Create an empty list X_new to store input features for semester 2 prediction
for each student in the dataset:
Calculate weighted semester 2 internal exam 1 (s2m1) and internal exam 2 (s2m2) scores
Get the student rating for semester 2 (rating2)
for each subject:
Add the input features [s2m1, s2m2, subject_difficulty_sem2, rating2] to X_new
Convert X_new to a numpy array
# Step 2: Scale the unseen data using the previously fitted StandardScaler
X_new_scaled = scaler.transform(X_new)
# Step 3: Predict semester 2 final scores
Use the trained neural network model to predict the final exam scores for semester 2
Predict the scores using the scaled input features (X_new_scaled)
Store the predictions in a variable y_pred
# Step 4: Reshape the predictions
Reshape the predicted final exam scores to match the original format
Reshape y_pred into a 2-dimensional array with the shape (number_of_students, number_of_subjects)
The variable predicted_final_sem2 now contains the predicted final scores for each student in semester 2.
Other thing was that I had to calculate the (expected) internal marks in this semester for each student too. The process was same as the one I explained in the beginning.
def score(m1, m2):
internal = (m1 + m2) / 4
if internal >= 12:
internal += 4
if internal > 30:
internal = 30
return ceil(internal)Then the bonus marks were distributed as per the need. After I got the internals, I summed it with the final score and estimated the grade and then calculated the SPI or GPA of that student.
credits = [5, 4, 4, 4, 3]
# Below block of code is actually inside a loop as per my program
# internals is a 2-D array with with the shape (number_of_students, number_of_subjects)
# same is with the predicted_final_sem_2
# each element in list is a list of all marks of a particular student
final_score = np.array(internals[i]) + np.array(predicted_final_sem2[i])
spi = 0
for j, k in enumerate(final_score):
if ceil(k) >= 85: # AA
spi += credits[j] * 10
elif ceil(k) >= 75: # AB
spi += credits[j] * 9
elif ceil(k) >= 65: # BB
spi += credits[j] * 8
elif ceil(k) >= 55: # BC
spi += credits[j] * 7
elif ceil(k) >= 45: # CC
spi += credits[j] * 6
elif ceil(k) >= 40: # CD
spi += credits[j] * 5
elif ceil(k) >= 35: # DD
spi += credits[j] * 4
else:
spi += 0 # FF
spi = round(spi / 20, 2)Plotting the training and prediction data
It is a common practice to plot the data of your models which helps you understand it (I used Matplotlib). Although there is no way to visualize this as there are four variables and plotting in 4 dimensions isn’t possible in our universe, one way is to plot a different scatterplot for each variable but as it was getting complicated, I plotted graphs for all students vs the variables and finals score for both semesters which gives you a pretty much idea about this.
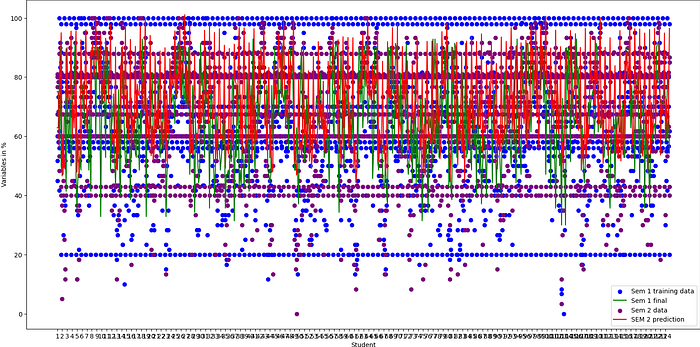
This was it! As the final scores haven’t been declared, I don’t have any way to check how accurate my model is but the predictions looks pretty accurate given I know my classmates. I’ll evaluate the model after the results get declared in around three months and update this.
Alternate approaches
Before trying the neural network, I tried with different models. The two which worked the best were Automatic Relevance Determination Regression (ARD) and Multiple Regression.
Multiple regression is a statistical technique used to analyze the relationship between a dependent variable (final exam scores) and two or more independent variables (four variables I used in NN). In multiple regression, the goal is to model and predict the dependent variable as a linear function of multiple predictors. The model tries to fit a line to the data. I also used Lasso Regression (L1 regularization) and Ridge Regression (L2 regularization). Regularization techniques are used to prevent overfitting and improve the generalization performance of the model. Overfitting occurs when the model fits the training data too closely, capturing noise and random variations rather than the underlying patterns. Regularization methods introduce additional constraints on the model’s parameters to control its complexity and prevent extreme parameter values.
An Automatic Relevance Determination (ARD) Regression System is a Bayesian Regression System that implements an ARD Regression Algorithm to solve a ARD Regression Task. The key feature of ARDRegression is its ability to automatically determine the relevance of each input feature during the training process. In traditional linear regression, all input features are assigned equal importance, and the model learns a single weight for each feature. However, in many real-world scenarios, not all input features may be equally important for predicting the target variable.
Variables and methods were same just the models were different. These models only work if the variables have linear relationship between them. The results were good but I wasn’t satisfied with them so I went ahead with Neural Network because it can understand non-linear relationships. You can always try with various models before choosing the best one for your task.
Conclusion / Summary
In this blog, I shared my experience of training a neural network to predict the final exam scores of my classmates. Using Python and a Multilayer Perceptron (MLP) model, I created a predictive system with four input nodes, two hidden layers, and one output node. The neural network aimed to estimate the final exam marks based on variables such as previous semester internal exam scores, subject difficulty and student ratings. I even devised a method to estimate the final exam marks based on current grade information.
Data preparation was challenging as I had to gather and format data from both the previous and current semesters. I decided to train the neural network on four key variables and associated weightings, allowing the model to learn from these factors and the final exam scores.
The training process involved the selection of appropriate neural network architecture, activation functions, and optimizer. I chose the popular ReLU activation function for its proven ability to overcome the vanishing gradient problem, contributing to improved model performance. StandardScaler was used to scale the variables before training, ensuring a level playing field for their influence.
After training the model, I used it to predict the final exam scores for the current semester. While I cannot validate the model’s accuracy until the actual results are declared in 2–3 months, the predictions seemed accurate based on my knowledge of my classmates’ performance.
Additionally, I devised a method to calculate the expected internal marks for the current semester based on the predicted final exam scores. This allowed me to estimate the students’ final grades and calculate their SPI or GPA.
To gain further insights into the model’s performance, I employed visualization techniques using Matplotlib. Although visualizing the data in four dimensions was not feasible, I plotted scatter plots for each variable against the final exam scores for both semesters.
Additionally, I explored alternative approaches like Multiple Regression and Automatic Relevance Determination Regression (ARD), which offered good results for linear relationships between variables. I ultimately chose the Neural Network for its ability to handle non-linear relationships, which seemed more appropriate for this prediction task.
In conclusion, training a neural network to predict exam scores has been an insightful experience. As the final exam scores are yet to be announced, I’m eagerly waiting to evaluate the model’s accuracy and effectiveness. I will provide updates on the model’s performance once the results are declared. Overall, this experience has been both challenging and rewarding, teaching me valuable lessons in data preparation, model building, and the importance of selecting the right approach for the task at hand.
